

It appears that AMD has recently filed and published a new patent titled “Chiplet-integrated Machine Learning Accelerators”, in which techniques for performing machine learning operations are outlined. AMD describes what the company calls a new MLA (Machine Learning Accelerator) chiplet design.
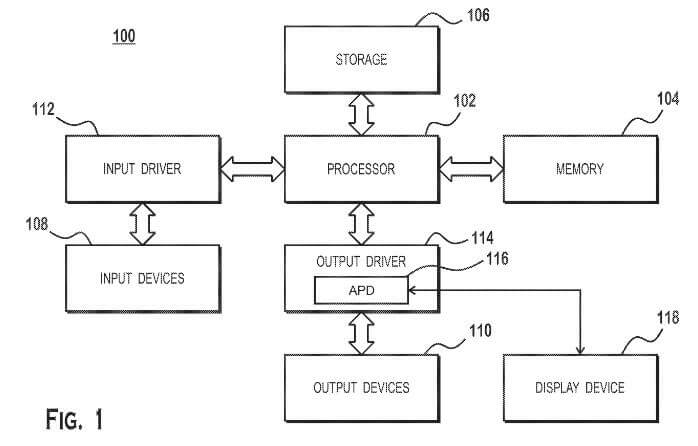
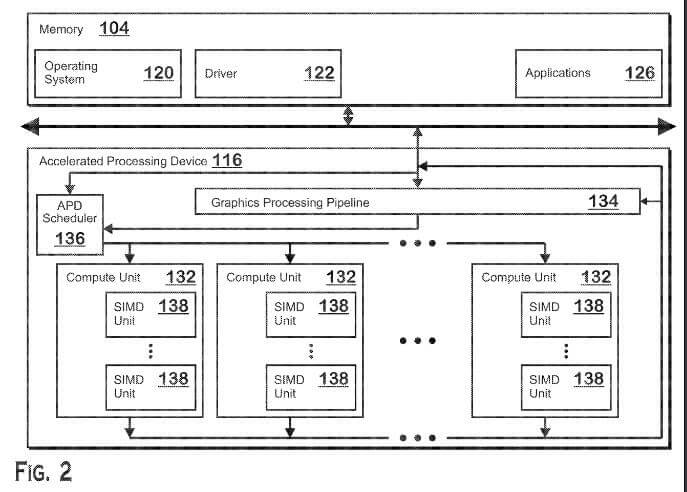
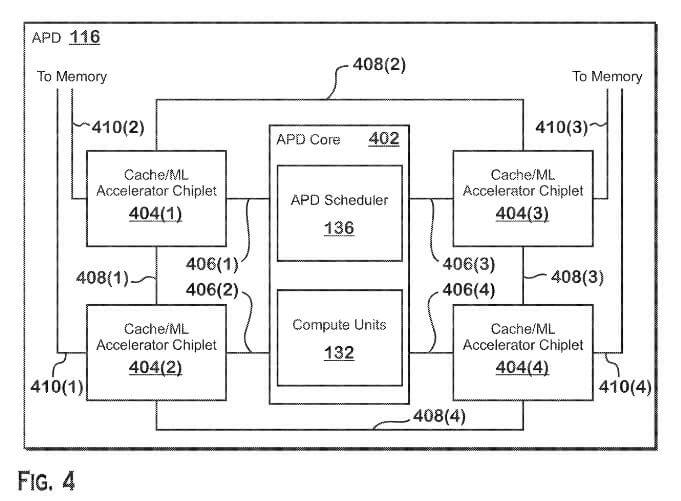
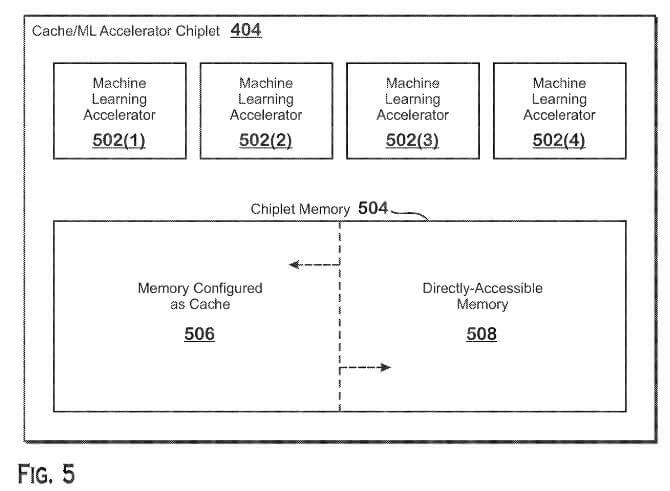
The patent application is for a machine-learning chiplet, which is going to be integrated into a package coupled with GPU cores as well as the cache, in order to create an “APD” or Accelerated Processing Device in AMD’s terminology. GPU cores here might refer to the upcoming RDNA 3 architecture, and the cache unit most likely being a version of AMD’s Infinity Cache design, if taken as an example.
The main purpose of this machine learning accelerator would be to accelerate machine learning such as matrix multiplication operations. This combined package of GPU, Machine-learning accelerator, and cache chiplet is collectively called an APD or “Accelerated Processing Device”.
Moreover, the APD described in this patent has a chiplet of both ML Accelerator as well as a cache on the same chiplet.
Through the inclusion of such a chiplet, AMD might be able to add some machine-learning capabilities to several of their designs in a modular way. Could this be AMD’s answer to Nvidia’s DLSS technique? I guess we will come to know about this later on when it gets implemented.
According to the patent’s description, different process nodes are being mentioned for each type of chiplet. This implies AMD might use different manufacturing technologies in this chiplet-based design.
Moreover, the memory modules of each MLA can be dynamically configured to be used as a cache (i.e. infinity cache), or as a directly accessible memory, depending on the scenario.
The patent basically describes how cache-requests from the GPU die to the cache chiplet can be achieved. Lastly, the MLA may be used as a physical interface between the APD core and a high tier memory. So the MLA is physically put between the APD core and the GDDR/HBM memory.
Based on the patent’s description, the chiplet is embedded in the substrate and can be used both as a silicon bridge, as well as an accelerator. As mentioned above, this design will also allow for on-the-fly usage of cache, or as a directly-addressable memory.
As the patent Abstract reads:
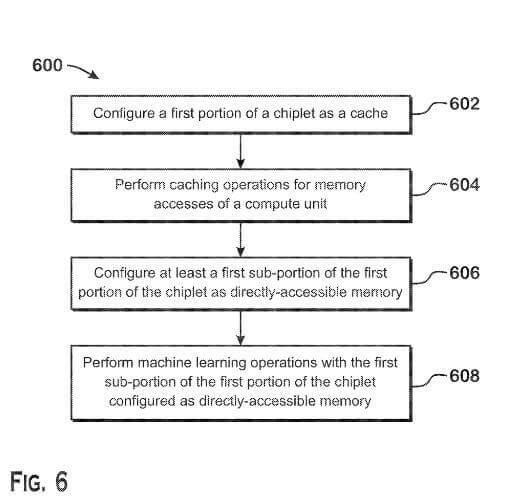
“Techniques for performing machine learning operations are provided. The techniques include configuring a first portion of a first chiplet as a cache; performing caching operations via the first portion; configuring at least a first sub-portion of the first portion of the chiplet as directly-accessible memory; and performing machine learning operations with the first sub-portion by a machine learning accelerator within the first chiplet.”
Machine learning is a rapidly advancing field. Improvements to hardware for machine learning operations such as training and inference are constantly being made. The methods provided can be implemented in a general purpose computer, a processor, or a processor core.
Suitable processors include, by way of example, a general purpose processor, a special purpose processor, a conventional processor, a digital signal processor (DSP), a plurality of microprocessors, one or more microprocessors in association with a DSP core, a controller, a microcontroller, Application Specific Integrated Circuits (ASICs), Field Programmable Gate Arrays (FPGAs) circuits, any other type of integrated circuit (IC), and/or a state machine.
Such processors can be manufactured by configuring a manufacturing process using the results of processed hardware description language (HDL) instructions and other intermediary data including netlists (such instructions capable of being stored on a computer readable media).
The results of such processing can be maskworks that are then used in a semiconductor manufacturing process to manufacture a processor which implements features of the disclosure.
The patent was filed on 07/20/2020, and published on 01/28/2021.
Stay tuned for more tech news!
Hello, my name is NICK Richardson. I’m an avid PC and tech fan since the good old days of RIVA TNT2, and 3DFX interactive “Voodoo” gaming cards. I love playing mostly First-person shooters, and I’m a die-hard fan of this FPS genre, since the good ‘old Doom and Wolfenstein days.
MUSIC has always been my passion/roots, but I started gaming “casually” when I was young on Nvidia’s GeForce3 series of cards. I’m by no means an avid or a hardcore gamer though, but I just love stuff related to the PC, Games, and technology in general. I’ve been involved with many indie Metal bands worldwide, and have helped them promote their albums in record labels. I’m a very broad-minded down to earth guy. MUSIC is my inner expression, and soul.
Contact: Email